The first homework on descriptive statistics and probability
Author
Yakub Rabiutheen
Published
September 20, 2022
Question 1
a
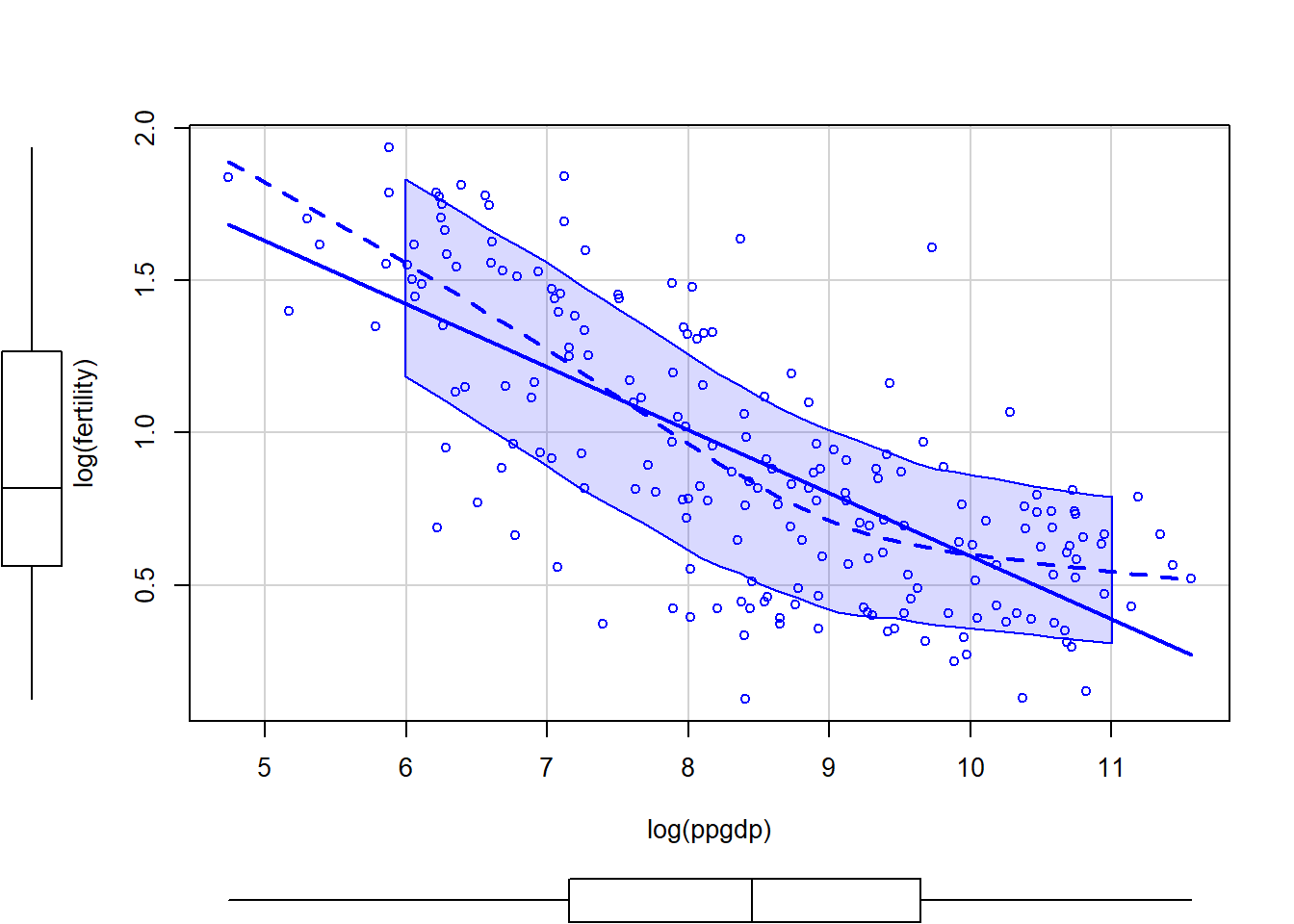
The data in the file UN11 contains several variables, including ppgdp, the gross national product per person in U.S. dollars, and fertility, the birth rate per 1000 females, both from the year 2009. The data are for 199 localities, mostly UN member countries, but also other areas such as Hong Kong that are not independent countries. The data were collected from the United Nations (2011). We will study the dependence of fertility on ppgdp.
Loading required package: car
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
Loading required package: effects
lattice theme set by effectsTheme()
See ?effectsTheme for details.
Code
library(smss)
Warning: package 'smss' was built under R version 4.2.2
Code
##load datadata(UN11)
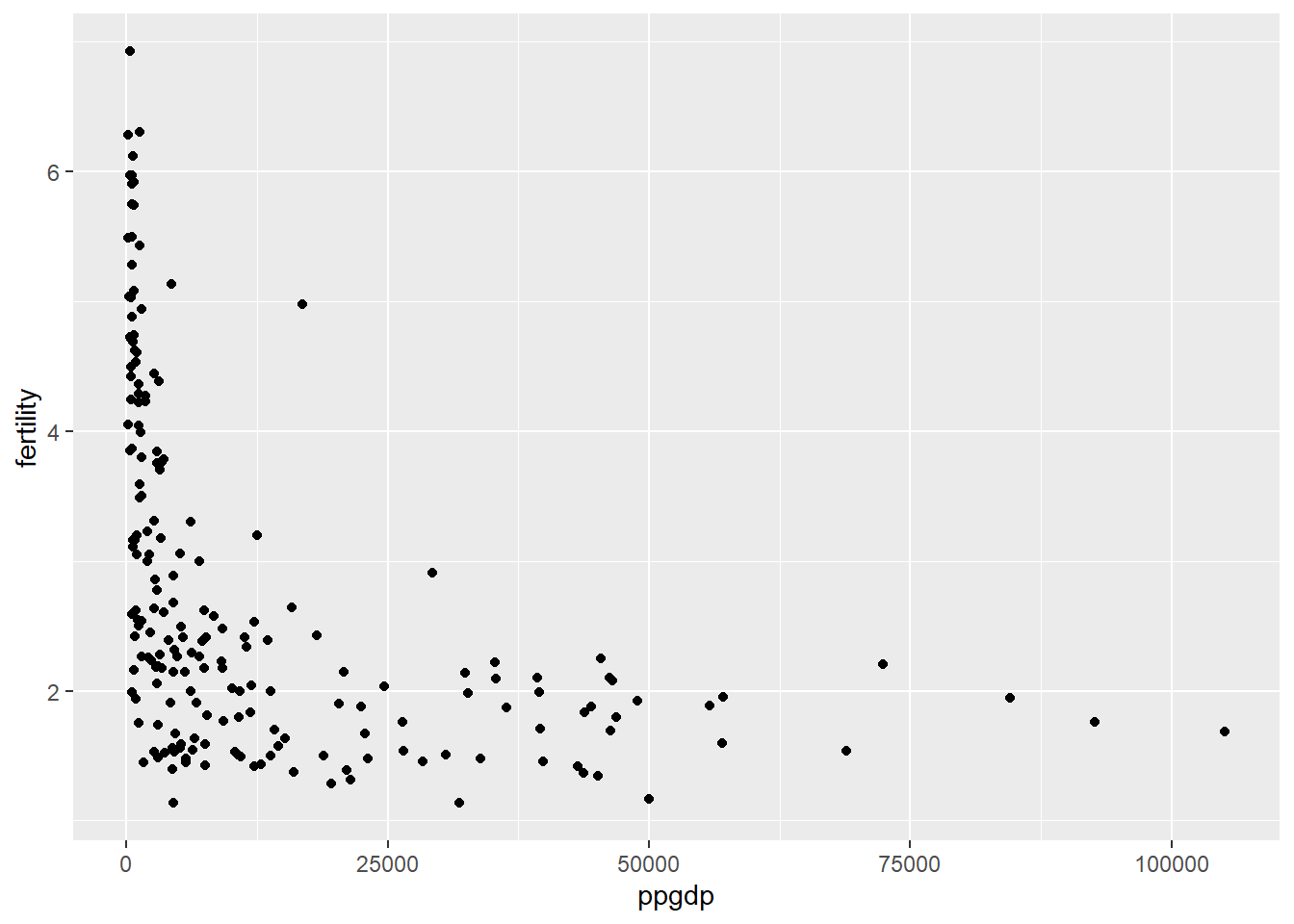
Qn 1.1.1
The predictor is ppgdp and the response is fertility.
Code
# Qn 1.1.1 Standard Scatterplotlibrary(ggplot2)ggplot(data = UN11, aes(x=ppgdp,y=fertility)) +geom_point()
Annual income, in dollars, is an explanatory variable in a regression analysis. For a British version of the report on the analysis, all responses are converted to British pounds sterling (1 pound equals about 1.33 dollars, as of 2016).
To convert from USD to GBP, the value of the response must be divided by 1.33. Same goes for the slope.
Question-2.b
How, if at all, does the correlation change?
Code
cor.test(usdollar,pound)
Pearson's product-moment correlation
data: usdollar and pound
t = 189812531, df = 8, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
1 1
sample estimates:
cor
1
Currency Changes do not affect correlation.
Question-3
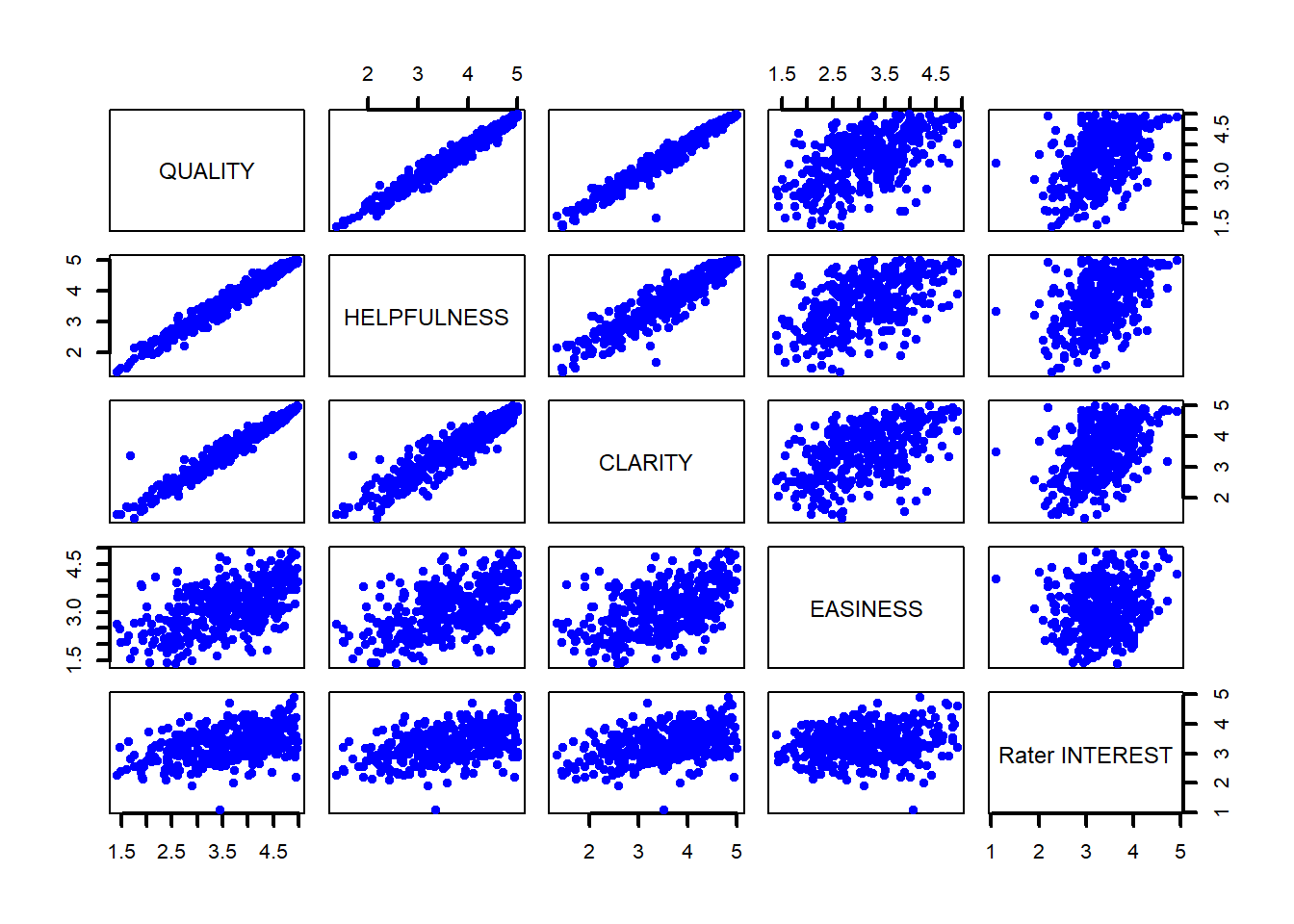
Water runoff in the Sierras (Data file: water in alr4) Can Southern California’s water supply in future years be predicted from past data? One factor affecting water availability is stream runoff. If runoff could be predicted, engineers, planners, and policy makers could do their jobs more efficiently. The data file contains 43 years’ worth of precipitation measurements taken at six sites in the Sierra Nevada mountains (labeled APMAM, APSAB, APSLAKE, OPBPC, OPRC, and OPSLAKE) and stream runoff volume at a site near Bishop, California, labeled BSAAM. Draw the scatterplot matrix for these data and summarize the information available from these plots. (Hint: Use the pairs() function.)
Code
pairs(water_supply,main ="Sierra Southern California Water Supply Runoff",pch =21, bg ="green")
Error in pairs(water_supply, main = "Sierra Southern California Water Supply Runoff", : object 'water_supply' not found
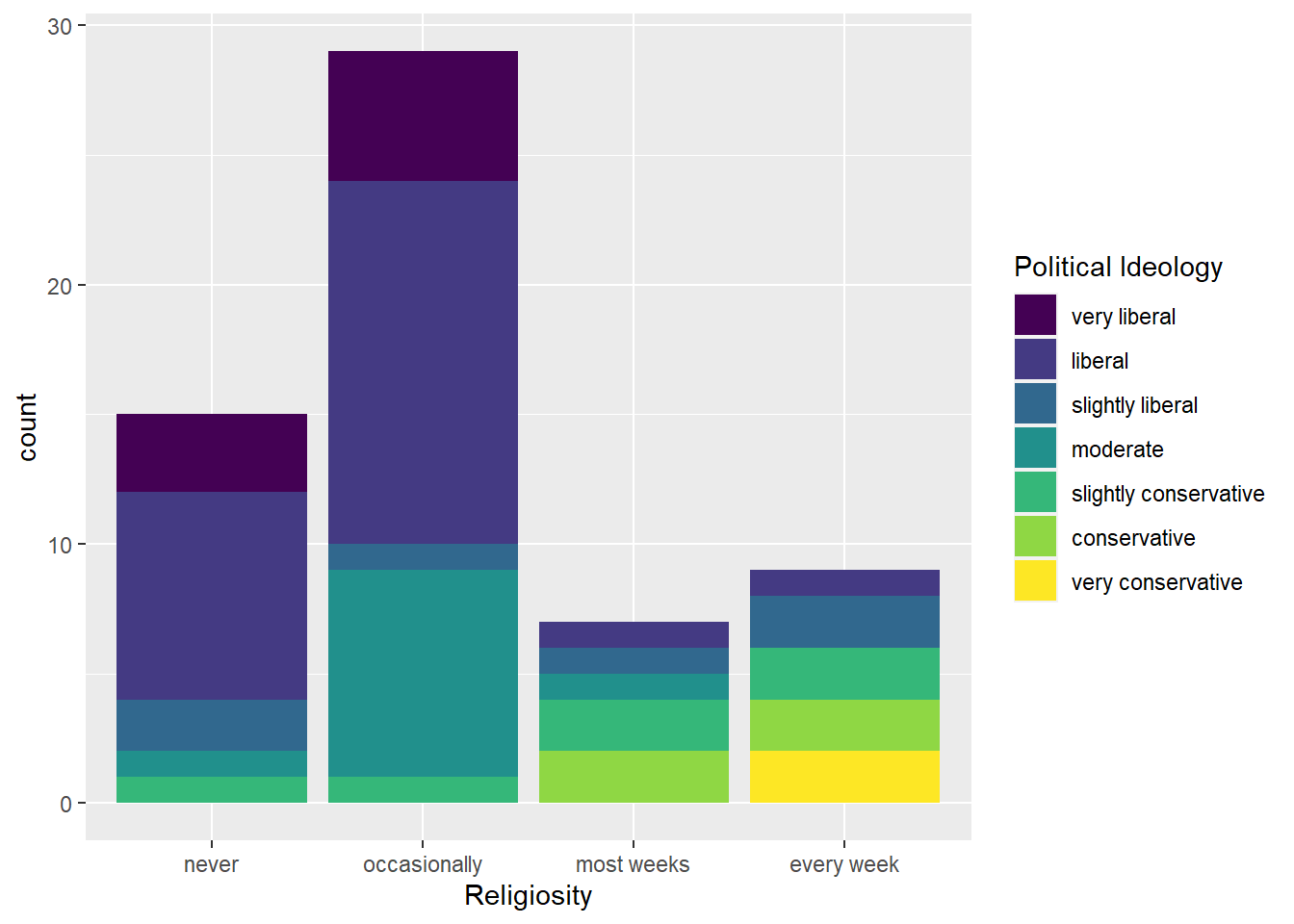
pi re hi tv
very liberal : 8 never :15 Min. :2.000 Min. : 0.000
liberal :24 occasionally:29 1st Qu.:3.000 1st Qu.: 3.000
slightly liberal : 6 most weeks : 7 Median :3.350 Median : 6.000
moderate :10 every week : 9 Mean :3.308 Mean : 7.267
slightly conservative: 6 3rd Qu.:3.625 3rd Qu.:10.000
conservative : 4 Max. :4.000 Max. :37.000
very conservative : 2
Source Code
---title: "Homework 3"author: "Yakub Rabiutheen"description: "The first homework on descriptive statistics and probability"date: "09/20/2022"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - hw1 - desriptive statistics - probability---# Question 1## aThe data in the file UN11 contains several variables, including ppgdp, the gross national product per person in U.S. dollars, and fertility, the birth rate per 1000 females, both from the year 2009. The data are for 199 localities, mostly UN member countries, but also other areas such as Hong Kong that are not independent countries. The data were collected from the United Nations (2011). We will study the dependence of fertility on ppgdp.```{r, echo=T}library(tidyverse)library(alr4)library(smss)``````{r, echo=T}##load datadata(UN11)```# Qn 1.1.1The predictor is `ppgdp` and the response is `fertility`.```{r}# Qn 1.1.1 Standard Scatterplotlibrary(ggplot2)ggplot(data = UN11, aes(x=ppgdp,y=fertility)) +geom_point()```# Qn 1.1.2```{r}# Log scatterplot.scatterplot (log(fertility) ~log(ppgdp), UN11)```# Question-2.aAnnual income, in dollars, is an explanatory variable in a regression analysis. For a British version of the report on the analysis, all responses are converted to British pounds sterling (1 pound equals about 1.33 dollars, as of 2016).```{r}usdollar<- (1:10)pound<-seq(1.33,13.3, length.out =10)slope<-(usdollar/pound)slope```To convert from USD to GBP, the value of the response must be divided by 1.33. Same goes for the slope.## Question-2.bHow, if at all, does the correlation change?```{r}cor.test(usdollar,pound)```Currency Changes do not affect correlation.## Question-3Water runoff in the Sierras (Data file: water in alr4) Can Southern California's water supply in future years be predicted from past data? One factor affecting water availability is stream runoff. If runoff could be predicted, engineers, planners, and policy makers could do their jobs more efficiently. The data file contains 43 years' worth of precipitation measurements taken at six sites in the Sierra Nevada mountains (labeled APMAM, APSAB, APSLAKE, OPBPC, OPRC, and OPSLAKE) and stream runoff volume at a site near Bishop, California, labeled BSAAM. Draw the scatterplot matrix for these data and summarize the information available from these plots. (Hint: Use the pairs() function.)```{r}pairs(water_supply,main ="Sierra Southern California Water Supply Runoff",pch =21, bg ="green")``````{r}lm_water_supply<-lm(BSAAM~APMAM+APSAB+APSLAKE+OPBPC+OPRC+OPSLAKE,data = water)summary(lm_water_supply)```The following variables OPBPC, OPRC, OPSLAKE are correlated with each other.## Q.4```{r}data("Rateprof")pairs(~Rateprof$quality+Rateprof$helpfulness+Rateprof$clarity+Rateprof$easiness+Rateprof$raterInterest, lwd=2, labels =c("QUALITY", "HELPFULNESS", "CLARITY", "EASINESS", "Rater INTEREST"), pch=19, cex =0.75, col ="blue")```The following variables “quality”, “clarity”, and “helpfulnes are correlated with each other.## Q.5```{r}##load datadata(student.survey)pi_conv <-as.numeric(student.survey$pi)re_conv <-as.numeric(student.survey$re)##run regression analysismodel1 <-lm(pi_conv ~ re_conv, data = student.survey)summary(model1)``````{r}##run regression analysismodel2 <-lm(hi ~ tv, data = student.survey)summary(model2)``````{r}library(smss)data("student.survey")ggplot(data=student.survey,aes(x=re,fill=pi))+geom_bar() +labs(x="Religiosity", fill ="Political Ideology")```As shown in the graph,there is a strong correlation association between religiosity and Political Idealogy.```{r}data("student.survey")ggplot(data=student.survey,aes(x=hi, y=tv)) +geom_point() +labs(x="High School GPA", y="Hours Watching TV") ```There is very little relationship betweeh watching TV and High School GPA.```{r}summary(student.survey[,c('pi', 're', 'hi', 'tv')])```